Datos bajo control público
Despliegue adaptable a nube soberana, privada, on-premise o arquitecturas híbridas según sensibilidad y criticidad.
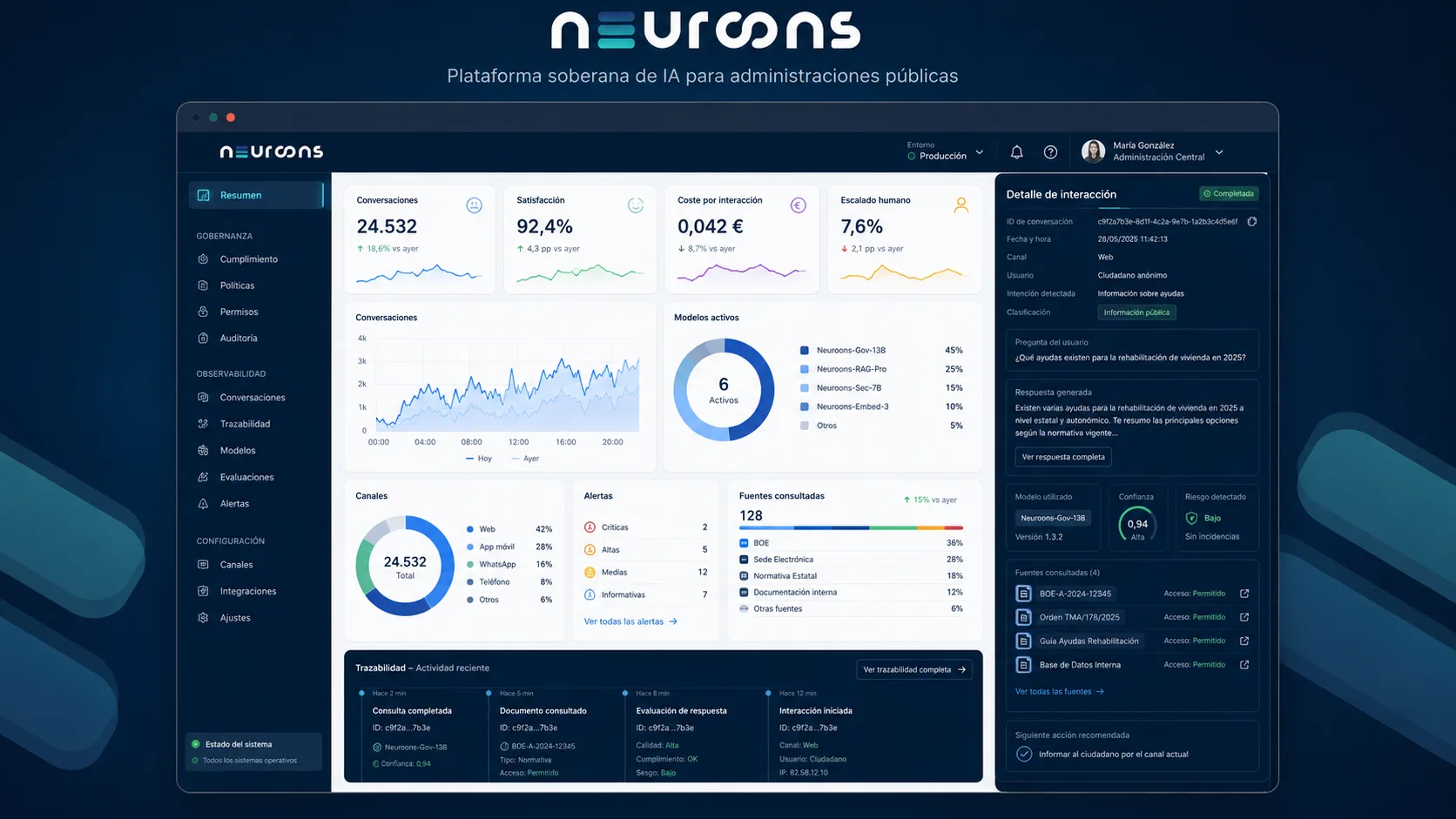
Infraestructura pública de IA
Administraciones más cercanas, resolutivas y gobernables. Neuroons convierte el conocimiento público en capacidades operativas reales sin perder el control sobre datos, procesos ni decisiones.
Neuroons no añade otra capa de complejidad a la administración. La ordena, la conecta y la convierte en una capacidad pública comprensible para ciudadanía y empleados.
El problema que resolvemos
Las instituciones operan con sedes electrónicas, registros, gestores documentales, expedientes, normativa, ERPs, CRMs e intranets. Pero el ciudadano solo ve si entiende qué debe hacer, si obtiene respuesta y si puede completar una gestión sin repetirlo todo.
Neuroons reduce esa brecha: interpreta la necesidad expresada en lenguaje natural, formula las preguntas imprescindibles y conduce al canal o procedimiento adecuado.

Nuestra propuesta de valor
Neuroons identifica procedimientos, solicita datos necesarios, recupera fuentes oficiales, valida requisitos, prepara documentos, activa flujos, deriva a un empleado público cuando procede y deja trazabilidad de cada paso.
La conversación no sustituye al procedimiento: lo prepara mejor.
Cinco capacidades
Respuestas comprensibles y verificables en el lenguaje de la persona.
Una persona pregunta “me he mudado”: Neuroons identifica qué trámites pueden verse afectados.Canales y sistemas existentes conectados sin reemplazar la arquitectura institucional.
La misma necesidad puede empezar en web, teléfono o intranet y conservar contexto.Flujos gobernados con datos, validaciones, documentos, derivaciones y checklists.
La IA prepara actuaciones; el procedimiento y el criterio público siguen gobernados.Registro de fuentes, modelos, coste, rol, respuesta, acción y escalado humano.
Cada respuesta puede auditarse y explicarse después.Modelos e infraestructuras elegibles, combinables y sustituibles.
Cloud soberana, privado, on-premise o híbrido según sensibilidad del dato.Una administración que se preocupa por llegar
Arquitectura técnica por capas
Neuroons se adapta a cloud, nube privada, nube soberana, on-premise, CPD local o configuraciones híbridas según sensibilidad del dato y criticidad del proceso.
Gobierno, datos y control público
Despliegue adaptable a nube soberana, privada, on-premise o arquitecturas híbridas según sensibilidad y criticidad.
Respuestas y acciones apoyadas en conocimiento institucional versionado, con registro de fuentes consultadas.
La IA prepara, orienta y escala. El criterio administrativo y los puntos de decisión siguen gobernados.
Registro de usuario, rol, modelo, coste, respuesta, acción ejecutada y punto de escalado.
Para quién trabajamos
Ayuntamientos, diputaciones, comunidades autónomas, ministerios, agencias, organismos reguladores y servicios públicos sectoriales que necesitan orientar, tramitar, auditar y medir con rigor.
El objetivo es llegar mejor a las personas sin perder gobernabilidad institucional.
Impacto
Ciudadanía
Menos confusión, esperas y desplazamientos. Más claridad y una administración percibida como presente.
Empleado público
Menos carga repetitiva, mejor acceso al conocimiento y más tiempo para juicio profesional cualificado.
Institución
Más eficiencia, consistencia, trazabilidad y control del dato. Menor riesgo de usos informales de IA externa.
Recurso descargable
Documento descargable de presentación para equipos institucionales.
Sesión de diagnóstico
Revisamos canales, procesos, fuentes de conocimiento y restricciones para identificar dónde Neuroons puede reducir fricción ciudadana, carga operativa y riesgo de uso informal de IA.
Solicitar diagnóstico Te responderemos para valorar viabilidad técnica, integraciones y encaje institucional.